Splunk Machine Learning Environment
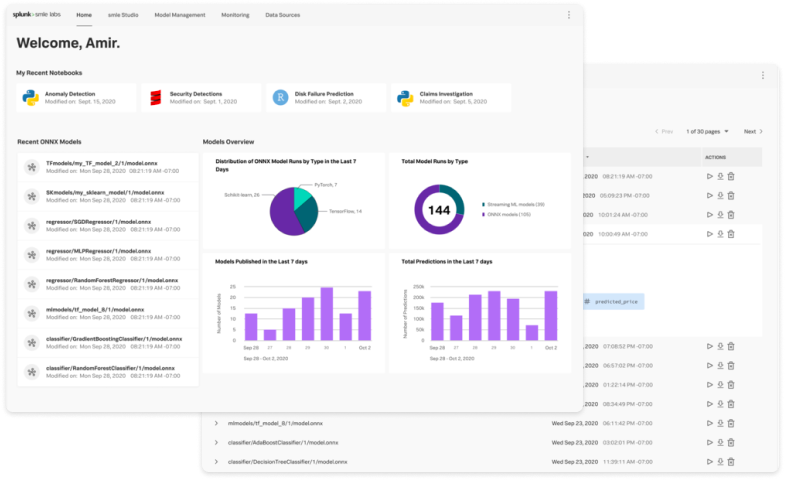
Splunk
◆June 2020 → May 2021
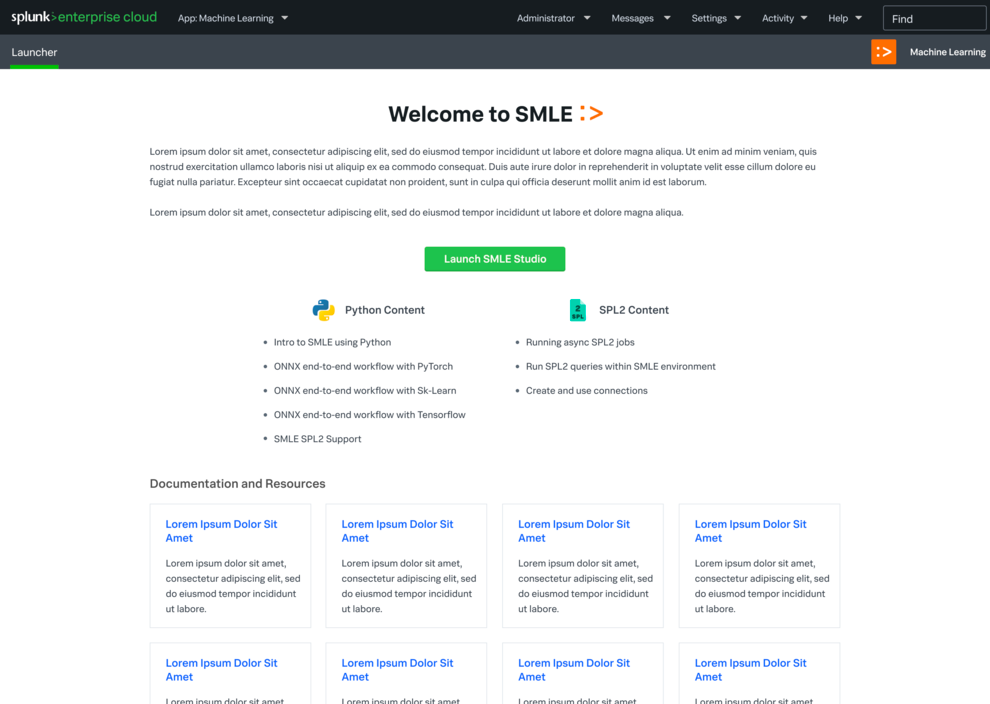
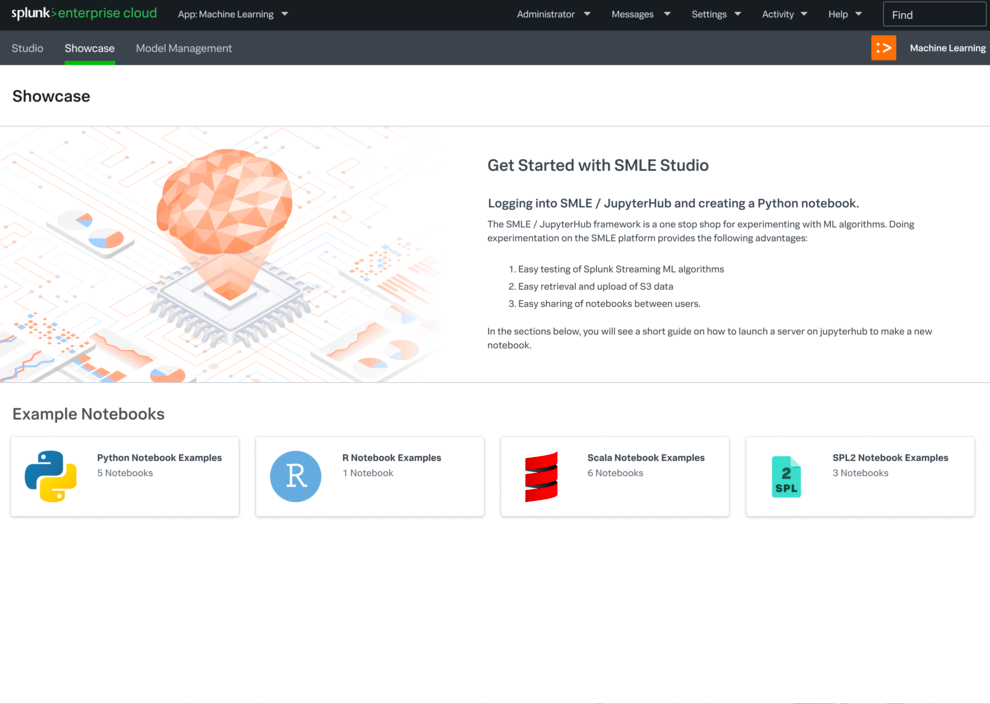
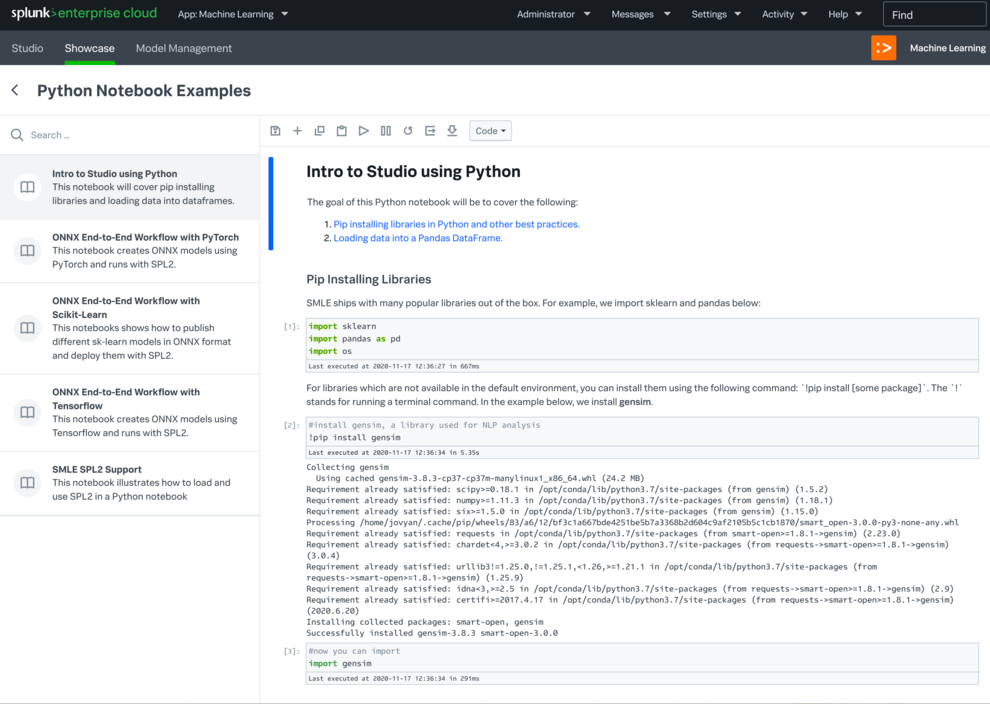
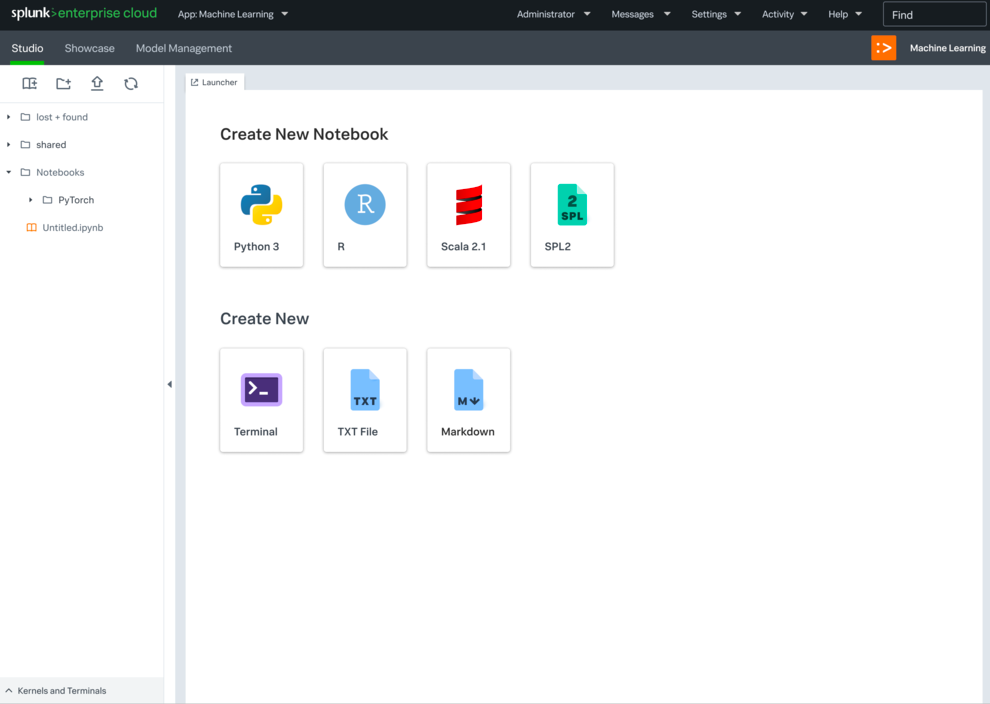
As machine learning started to take hold in the world at large, more and more Splunk users were craving a place where they could experiment, operationalize, and collaborate on their custom ML algorithms within the Splunk ecosystem. Users craved the ability to truly develop and customize an algorithm and build a pipeline around it. Staying within the Splunk ecosystem was also imperative to help streamline users' data pipelines and deployments, and utilize Splunk Processing Language (SPL) within their process.
The Splunk Machine Learning Environment (SMLE) was developed, cloud first, in order to address these needs and pain points.
There were two main efforts of the platform: SMLE Lab and SMLE Studio. Before we developed anything though, I co-led an intensive user research study to understand needs more thoroughly.
Previously, the target audience for machine learning initiatives at Splunk had been the Citizen Data Scientist — someone who generally knew about machine learning, but did not study it heavily or was a subject matter expert on the topic.
To build a deeper understanding of the user base SMLE was targeting, we designed and ran a large scale contextual inquiry study to talk to all targeted personas — Data Scientists, ML Engineers, and Applied Researchers — with the goal of learning the intricacies of their day to day experiences. This included what tools they used, what their main process was in their projects, where in the process they spent the most time, and the grating pain points they encountered.
Research Brief and Sessions
To help guide the sessions and ensure we had a good basis for discussion, we put together a research brief and guide. Twelve participants were scheduled, with at least two people in each role we wanted to target. They had a variety of expertise and focus area. Before beginning the interviews, we also synced with PM and Engineering to review our plan and align in case there were any missing bits of information.
After that, we began facilitating the sessions! We had two or three sessions per week and spread the sessions across a four week span. After each session wrapped, we transcribed the sessions as quickly as possible so we could capture direct quotes and maintain as much context as possible.
 Contextual inquiry discussion guide.
Contextual inquiry discussion guide.
Consolidation and Deliverables
Once we finished the sessions and transcriptions, we had around 64 pages of data to digest and synthesize.
From these 60+ pages, I created three robust mental models for the roles we spoke with. These ended up being pretty verbose themselves because we had such rich sessions, detailing what these roles’ day to day jobs and experiences were. To distill this data more, I created corresponding one pagers for each mental model.
In addition to these one pagers and detailed mental models, I also created user journeys for each role and added context to each with direct quotes referencing potential design opportunities and common pain points.
 Session consolidation document.
Session consolidation document.

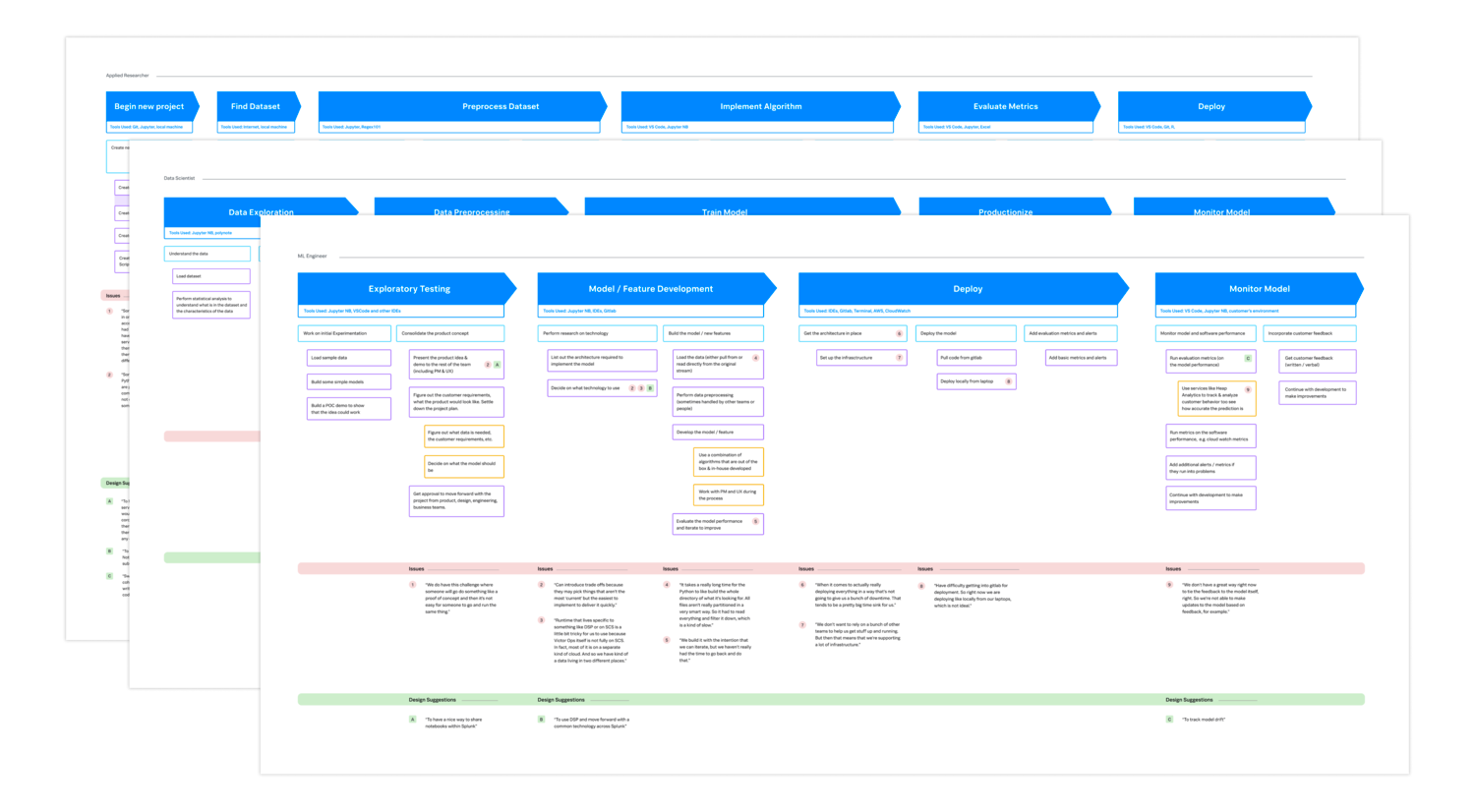
Contextual Inquiry
After initial brainstorming and explorations, there were quite a lot of assumptions and missing information about our users and their day to day work. We knew that if we didn't interview folks to get some actual feedback about lived experience, we'd miss the mark with our designs and roadmap.
The research plan developed focused on contextual inquiry to gain the foundational understanding of our users we needed. The goal was to get a particular idea of the tools / environments they used, where they spent the most time, and what glaring pain points they had.
To read about this study more in depth, take a look the Contextual Inquiry UXR.
Session consolidation document.
Discovery + Initial Brainstorming

Designs
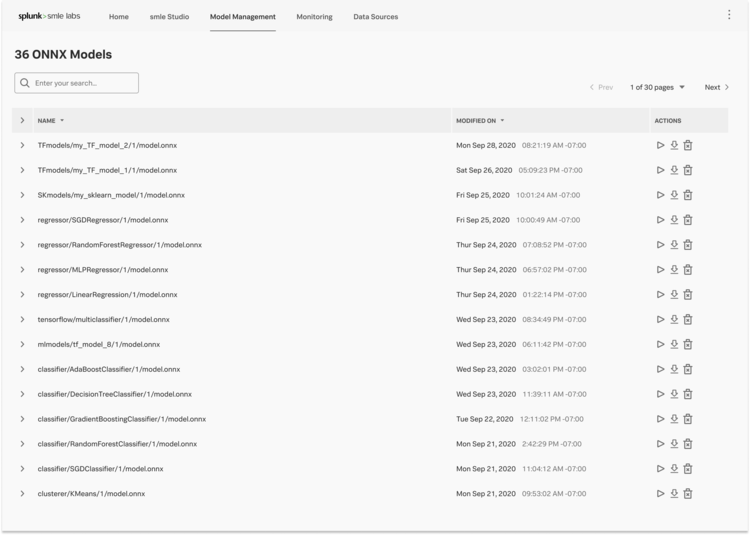
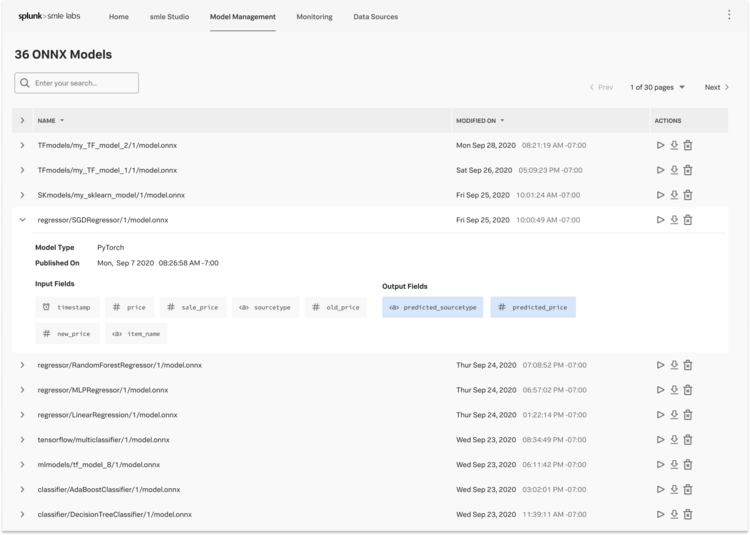
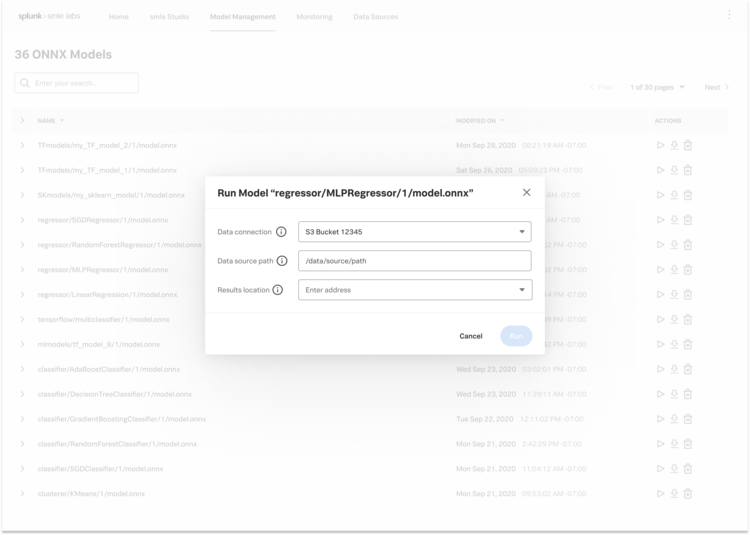
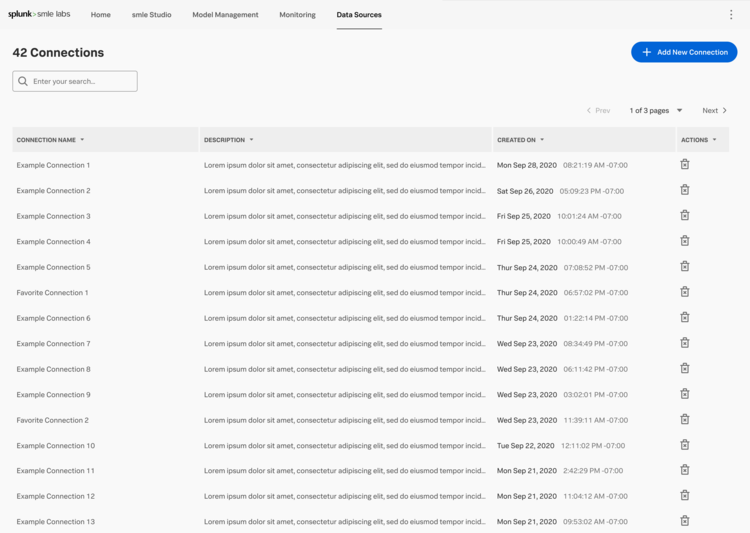

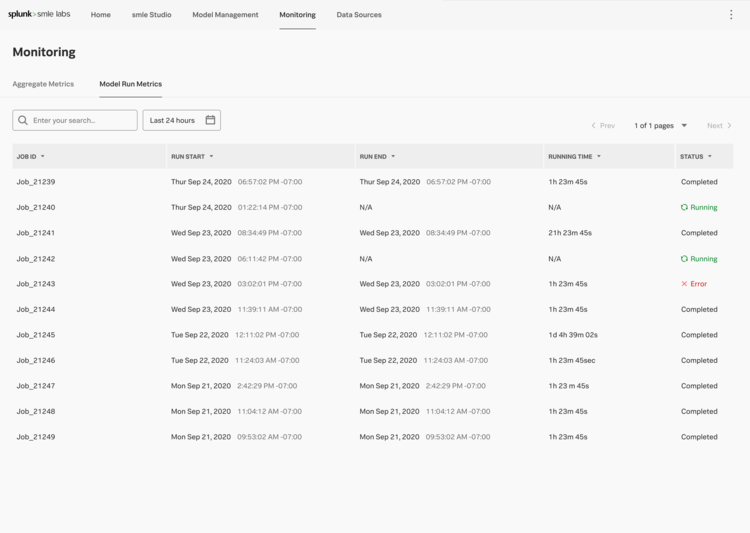
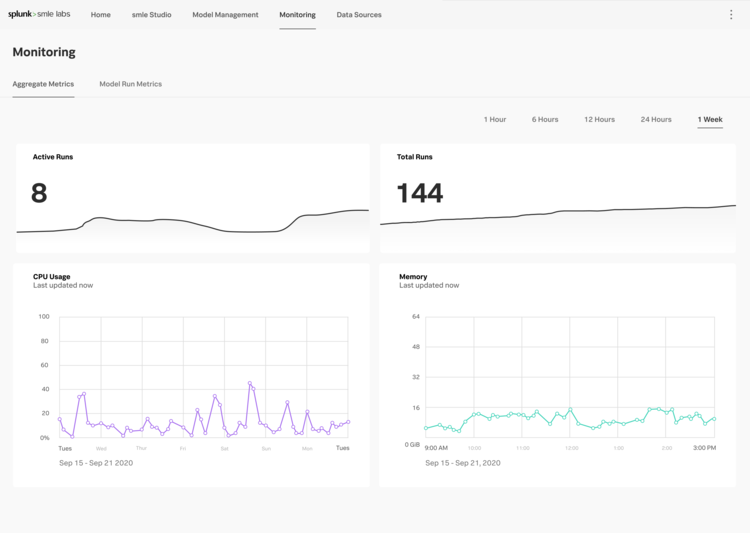
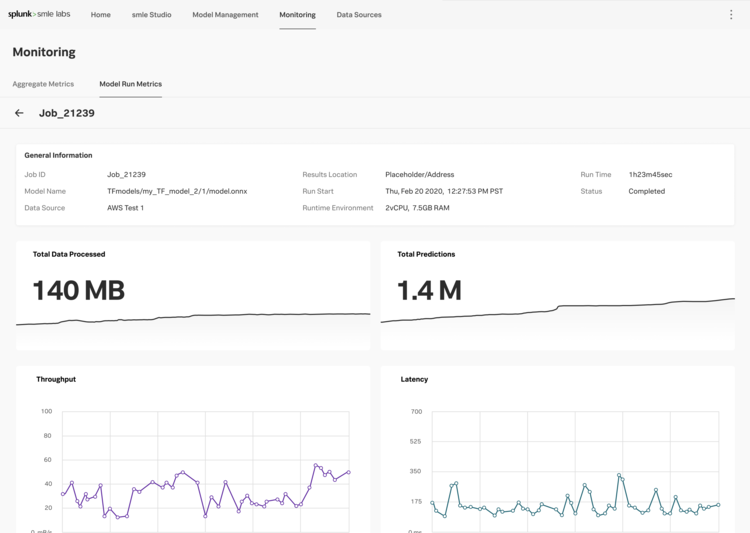
Initial Explorations

User Research
Jupyter Notebooks and Lab are cornerstones within the data science community, so we needed to talk to actual users about their preferences, what they use in Jupyter, and what pain points existed. Because of this, we decided to do a small scale user research study.
We talked to four users with a range expertise and needs. The first portion of the sessions focused on what their environments / projects looked like and how they used Jupyter. They then gave feedback on design directions we were considering. The consistent takeaway was that much of Jupyter’s UI was either not used or redundant, and there were only a few primary actions that needed to be maintained.
 Study consolidation document.
Study consolidation document.
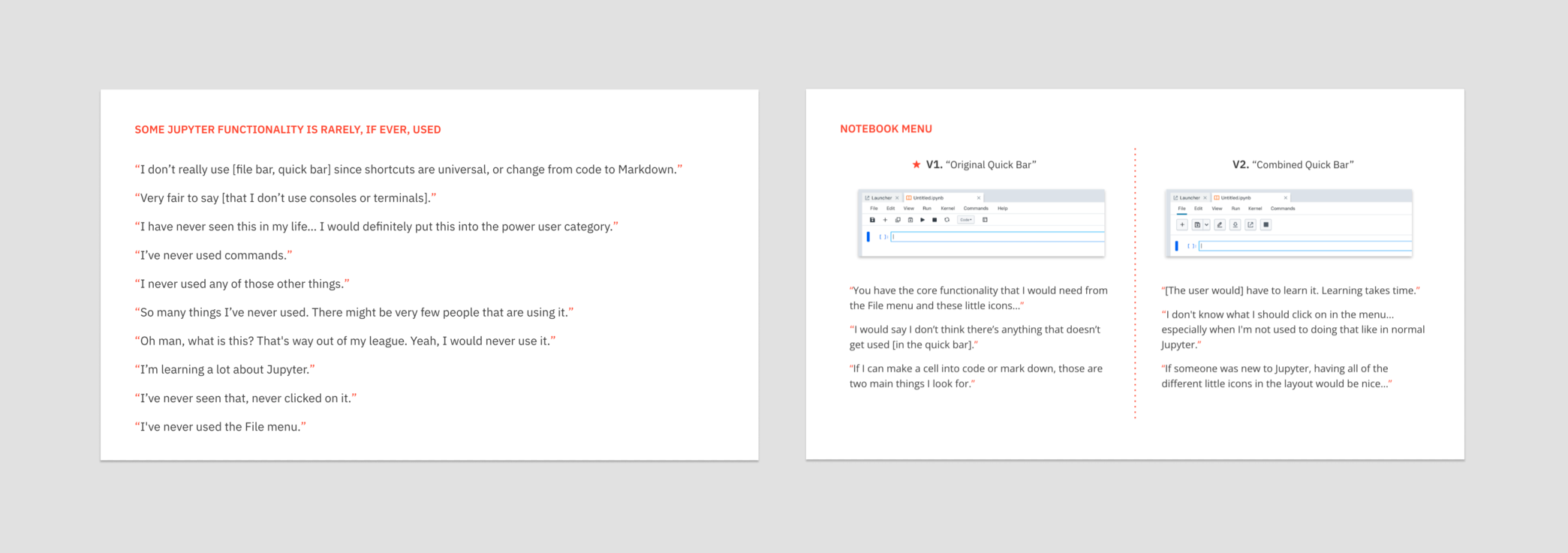
Navigation Explorations

Designs